





















Why AI fails without a single source of truth
According to S&P Global Market Intelligence's 2025 survey of over 1,000 organizations across North America and Europe, 42% of companies abandoned most of their AI initiatives that year — up from just 17% in 2024. The average organization scrapped 46% of AI proof-of-concepts before they ever reached production. [S&P Global Market Intelligence, 2025 Enterprise AI Survey]
The instinct is to blame the model, the vendor, or the use case. The real culprit is almost always upstream: the data.
When content and customer data live across disconnected systems, AI has no reliable foundation to work from. It cannot reconcile contradictions. It cannot fill gaps. It surfaces outputs that no one trusts enough to act on, and the initiative dies not because the technology failed, but because the data was never ready for it.
According to Gartner, through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data. [Gartner, Data Quality Issues] This is the "garbage in, garbage out" problem at enterprise scale. And it is architectural, not accidental.
The fix is not a better model. It is a single source of truth.
The challenge: Fragmented content and data silos
What happens when data lives in multiple systems?
Most large organizations did not set out to build a fragmented data landscape. It happened gradually — a CRM here, a marketing platform there, a legacy CMS that predates the current IT team. Before long, customer data lives across various systems that were never designed to talk to each other.
The operational cost is real. When business data is scattered across different systems, teams end up manually reconciling the same information in parallel — duplicating work, introducing errors, and slowing down every process that depends on accurate inputs. For any AI initiative, this is fatal. Machine learning models cannot compensate for data silos. They amplify them.
The cost of human error and inconsistent information
43% of organizations participating on Informatica's CDO survey identified data quality and readiness as a top obstacle to AI success. Above lack of technical maturity, and the shortage of skills and data literacy. [The global CDO Insights 2025]
Sounds familiar? It should. When the same customer appears as "Acme Corp" in the CRM and "ACME Inc." in the content platform, the AI sees two different entities. When product information is updated in one system but not others, business users are making decisions on stale data. Inaccuracy compounds fast at scale. Operational costs rise, customer experiences suffer, and the entire organization loses confidence in the outputs AI is supposed to deliver.
Defining the single source of truth in content management
What is a single source of truth (SSOT)?
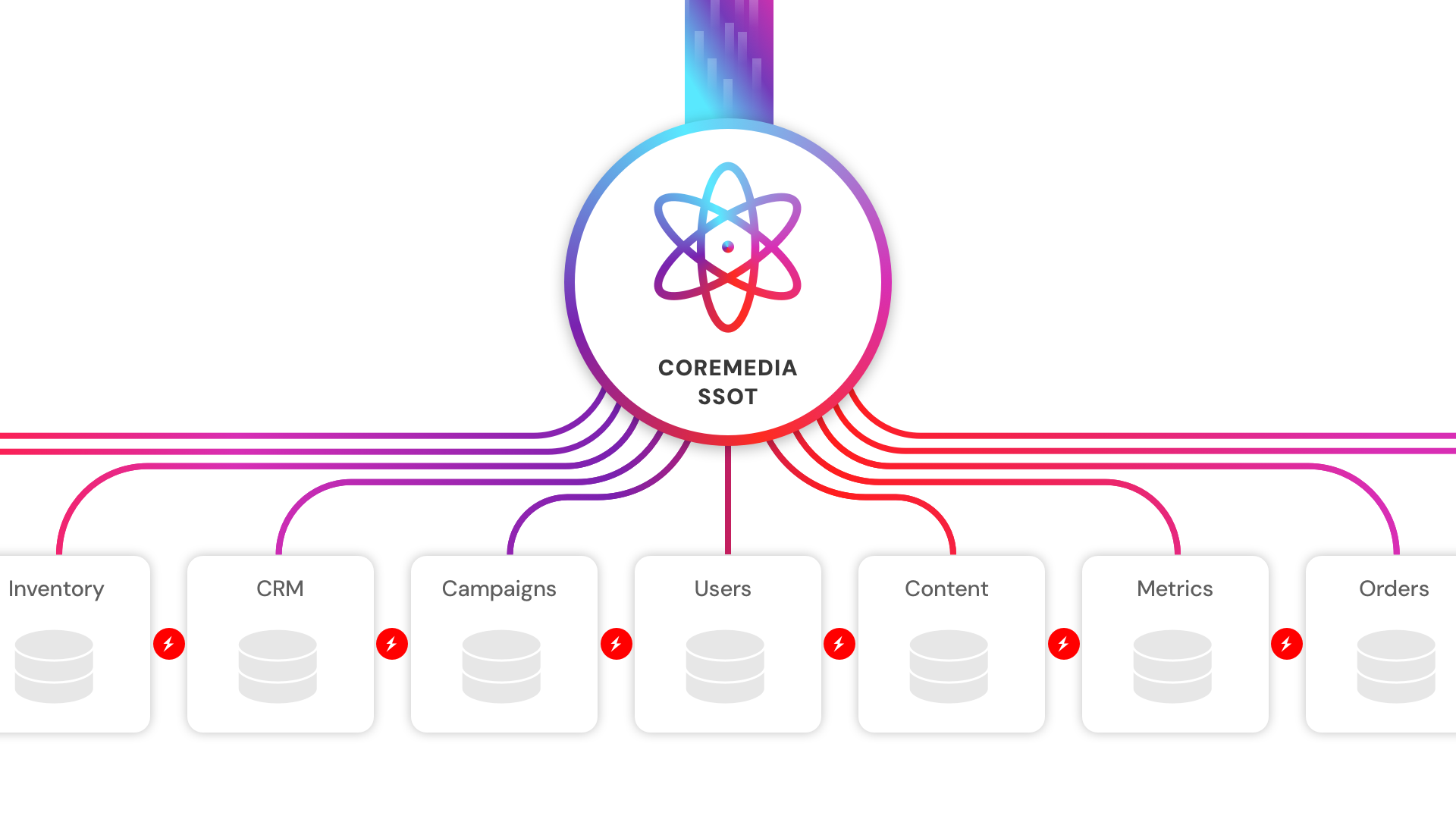
A single source of truth is a single reference point for all data and content within an organization. One system of record that every other tool, team, and process draws from. In content management, this means that all customer-facing content, from web pages to app notifications to in-store digital displays, originates from and is governed by one central platform.
The distinction matters because a single source of truth is not just about where data lives. It is about what happens when it changes. In an SSOT model, an update made in one place propagates consistently across every channel and system. There is no version drift, no parallel editing, no reconciliation required.
For AI, this is the difference between feeding a model reliable, structured, governed inputs and feeding it a mismatch of contradictions.
SSOT architecture vs. traditional data architecture
Traditional data architecture tends to accumulate over time: a data warehouse here, a separate content platform there, point integrations stitched together as needs emerge. The result is a system where data accuracy depends on how recently someone last synchronized the various systems, which is rarely recent enough.
SSOT architecture inverts this. Rather than treating the data warehouse as the end destination, the single source of truth becomes the origin. Content and data are governed at the source, structured consistently, and made available downstream in a form that systems — including AI — can actually use. The information system becomes an active asset, not a passive archive.

How a single source of truth empowers enterprise AI
Feeding AI with accurate and reliable data
AI is only as good as what it is trained on and what it retrieves in production. Accurate data at the input stage is not a nice-to-have. It is the minimum requirement for outputs that business leaders can act on. When content and customer data flow from a governed single source, the AI has a consistently reliable foundation to work from. Structured, version-controlled, governance-checked data produces outputs that editors, analysts, and executives can actually trust.
Enabling data driven decisions
Many organizations describe themselves as data-driven. Fewer actually are. The gap is usually a shortage of data that is clean, accessible, and trusted enough to inform critical decisions without a manual audit first.
A single source of truth changes the economics of decision-making. When business users know that the data behind a report or AI recommendation comes from a governed, centralized platform, they can act on it with confidence. Data-driven decisions require data that is actually reliable.
Maintaining data consistency at scale
Data consistency is easy when you have one team, one system, and one channel. It becomes the hardest problem in the enterprise as you add markets, business units, and digital touchpoints.
A single source of truth addresses this by design. Rather than hoping that multiple systems stay synchronized, the SSOT model ensures that every downstream consumer — whether that is a personalization engine, an AI recommendation system, or a regional content team — draws from the same governed production data. Data accuracy does not degrade as the organization grows. It scales with it.
Key components of AI-ready data management
The crucial role of data governance
Data governance is the set of rules, roles, and processes that determine how an organization's data is created, maintained, and used. Without it, a single source of truth is just a single point of failure, a centralized system with no controls around what goes in or who can change it.
Effective data governance covers access controls, data quality standards, and compliance requirements. For regulated industries such as financial services, public sector, healthcare, it is not optional. But even for organizations without strict regulatory requirements, data governance is what separates business data that AI can trust from data that AI will misuse.
Data management without governance is infrastructure without policy. Both are required for enterprise AI to function at scale.
Unifying data across business units
One of the structural challenges in large organizations is that departments often accumulate their own tools, their own processes, and their own copies of the same data. Unifying and integrating data across these structures is not primarily a technical problem, it is an organizational one.
The technical layer matters: integrations need to be robust, the platform needs to support the full range of content types and data sources, and access needs to be appropriately permissioned. But the deeper work is agreeing on what the single source of truth should contain, who owns each content type, and what the workflows look like when the same data is used by multiple teams. When those decisions are made well, the same data can serve marketing, product, IT, and AI, without duplication or conflict.
Bridging the gap between the data team and business users
A data team that produces accurate, well-governed data is only valuable if business users can act on it. In many organizations, this translation layer breaks down. The data analyst publishes a report; the marketing team does not trust it because they cannot trace where it came from. Data analytics tools produce insights that sit unread because the audience does not have the context to interpret them.
A single source of truth reduces this friction. When business users know that the content and data they see in their tools comes from the same governed source as the AI's inputs, the gap narrows. Outputs become interpretable, attribution becomes clear, and the data team's work translates into action rather than sitting in a dashboard.
The CoreMedia advantage: A secure, compliant data container
Transforming your CMS into a strategic asset
Most organizations think of their CMS as a publishing tool. The CoreMedia Experience Platform is built to be something different: a strategic asset that acts as the governed foundation for every content, customer data and experience delivery, all within one composable architecture.
This means structured content models, clear ownership workflows, enterprise-grade access controls, and the flexibility to serve content across every channel without duplication. It means that when your AI system needs customer information or product content, it draws from a single governed source rather than stitching together outputs from various systems. And it means that as your business opportunities evolve — new markets, new channels, new AI use cases — the foundation scales with them rather than requiring a rebuild.
A complete view of customer data
Personalization without a complete view of customer data is guesswork at scale. When customer information is fragmented across a CRM, an analytics platform, and a legacy CMS, none of those systems has the full picture — and neither does the AI.
- CoreMedia's built-in Customer Data Platform (CDP) solves this at the source. It consolidates customer data from all touchpoints into unified profiles, built entirely on first-party data — which matters as third-party cookie restrictions tighten across markets. The result is a comprehensive view of each customer that feeds directly into experience delivery, without requiring a separate CDP vendor or a manual data integration layer.
- A single source of truth only delivers value if the data in it can be acted on immediately. CoreMedia's Real-time Personalization engine is built directly into the same platform that manages content. There is no lag between a customer signal and the experience that responds to it. Audience segments update dynamically, content variants are delivered based on live behavioral data, and A/B testing runs inline without exporting data to an external tool. This is what separates real-time personalization from batch personalization: the data and the delivery mechanism share the same governed foundation, so the response happens at the moment of intent — not the following morning.
- CoreMedia KIO is the AI copilot embedded natively inside the CoreMedia Experience Platform. Unlike generic AI tools that operate in isolation, CoreMedia KIO has direct access to customer data, real-time performance metrics, and brand guidelines — all from the same governed source. It generates content, surfaces behavioral insights, and supports contact center agents, but every suggestion it produces requires editor approval before execution. Human control remains intact at every step. Its outputs are consistently reliable — grounded in the organization's actual data, not a disconnected model inference. That is the practical difference between AI that helps and AI that misleads.
Case study: How Dutch Railways (NS) built a future-proof content architecture
Overcoming siloed content assets for better operations
NS Dutch Railways is the principal passenger railway operator in the Netherlands, moving over a million travelers per workday across a network served by a website, mobile app, and digital touchpoints at stations.
Behind that scale sat a fragmented IT landscape. Multiple CMSs were used by different departments. Content was duplicated, inconsistently maintained, and difficult to update across channels. When the same information needed to appear on the website, the app, and a station display, it required manual effort in multiple systems — introducing the exact kind of human error that scales badly and poisons the data quality that AI depends on. With more than 1,500 digital professionals spread across multiple operational clusters, the coordination overhead was significant, and the risk of siloed data producing inconsistent passenger experiences was constant.
A foundation for insight generation and future AI
NS partnered with IBM iX and CoreMedia to build a unified, headless content platform that would serve as a single source of truth for all passenger-facing content. The goal was to build an architecture capable of real-time data delivery and future AI readiness.
CoreMedia now connects to a static site generator that pre-builds HTML pages for rapid delivery, ensuring consistent speed. All communication channels are unified through an integration layer, with content and assets managed from one source. The result is a modular, scalable omnichannel content infrastructure, reducing human error, supporting real-time data updates, and providing the governed data foundation that future AI and insight generation use cases will require.
NS illustrates what this shift actually looks like at enterprise scale: moving from fragmented source systems to a single governed platform is not a one-time project. It is a structural decision about what kind of organization you want to be when AI becomes central to your business process.
Steps to implement an AI-ready CMS infrastructure
Auditing your current content sets
Before you can build a single source of truth, you need to know where your business content actually lives. This means mapping your data sets across systems and multiple sources — what content exists, where it originates, who owns it, and how it is currently synchronized (or not). The audit is not glamorous, but it is the only way to understand the true scope of your fragmentation. Most organizations find more sources than they expected.
Establishing data access and security
Once you understand what you have, the next step is designing the governance layer for the new system. This covers data access — who can read, create, or modify which types of content — as well as the approval workflows that ensure quality before publication.
Migrating to a single system requires decisions about what gets brought forward and what gets deprecated. Not all data sets are worth migrating. A new system that inherits the inconsistencies of the old one has not solved the problem, it has centralized it. Access controls, ownership structures, and editorial workflows need to be defined before migration begins, not after.
Conclusion: Secure your AI future today
Your next steps
The organizations generating real, measurable returns from AI in 2026 share a common characteristic: they treated data infrastructure as a strategic prerequisite, not an afterthought. They invested in the unglamorous work of data governance, unifying data across systems, and establishing a single source of truth before expecting AI to deliver.
The technical infrastructure for AI is available to every enterprise. The governance infrastructure — the governed, consistent, reliable data foundation — is what separates the 5% generating documented AI value from the majority that cannot get past the proof-of-concept stage.
If your AI initiatives are stalling, the answer is almost never a better model. It is a better foundation.
Request a demo to explore how the CoreMedia Experience Platform can become the single source of truth for your enterprise AI strategy.



