





















Warum KI ohne Single Source of Truth scheitert
Laut der 2025 Enterprise-AI-Survey von S&P Global Market Intelligence haben 42 Prozent der Unternehmen im Jahr 2025 den Großteil ihrer KI-Initiativen eingestellt – ein Anstieg von 17 Prozent im Jahr 2024. Im Durchschnitt wurden 46 Prozent der AI-Proof-of-Concepts verworfen, bevor sie überhaupt in die Produktion gelangten.
Der naheliegende Reflex ist, das Modell, den Anbieter oder den Use Case verantwortlich zu machen. Die eigentliche Ursache liegt jedoch fast immer eine Ebene darunter: bei den Daten.
Wenn Content- und Kundendaten über mehrere, voneinander getrennte Systeme verteilt sind, fehlt der KI eine verlässliche Grundlage. Widersprüche können nicht aufgelöst werden, Informationslücken bleiben bestehen. Die Ergebnisse sind nicht vertrauenswürdig genug für echte Entscheidungen. Die Initiative scheitert dann nicht an der Technologie, sondern daran, dass die Daten nie KI-ready waren.
Laut Gartner werden bis 2026 rund 60 Prozent der KI-Projekte scheitern oder eingestellt, wenn sie nicht auf hochwertigen, KI-fähigen Daten basieren. Es handelt sich dabei um das klassische „Garbage in, garbage out“-Problem im Enterprise-Maßstab. Und dieses Problem ist architektonisch bedingt, nicht zufällig.
Die Lösung ist kein besseres Modell. Die Lösung ist eine Single Source of Truth.
Die Herausforderung: Fragmentierte Inhalte und Datensilos
Was passiert, wenn Daten in mehreren Systemen liegen?
Die meisten großen Organisationen haben Datenfragmentierung nicht bewusst aufgebaut. Sie ist schrittweise entstanden: ein CRM hier, eine Marketing-Plattform dort, ein Legacy-CMS aus einer früheren IT-Generation. Mit der Zeit entsteht eine Landschaft, in der Kundendaten über mehrere Systeme verteilt sind, die nie dafür konzipiert wurden, miteinander zu kommunizieren.
Die operativen Kosten sind erheblich. Wenn Business-Daten über verschiedene Systeme verstreut sind, müssen Teams dieselben Informationen parallel manuell abgleichen. Das führt zu doppelter Arbeit, erhöht die Fehlerquote und verlangsamt alle Prozesse, die auf konsistente Daten angewiesen sind. Für KI-Initiativen ist das besonders kritisch. Machine-Learning-Modelle können Data-Silos nicht kompensieren, sie verstärken sie.
Die Kosten von menschlichen Fehlern und inkonsistenten Informationen
Laut der CDO-Survey von Informatica sehen 43 Prozent der befragten Organisationen Datenqualität und Datenbereitschaft als zentrale Hürde für den Erfolg von KI, noch vor technischer Reife oder fehlenden Skills und Data-Literacy.
Das Problem ist bekannt: Wenn derselbe Kunde im CRM als „Acme Corp“ und in der Content-Plattform als „ACME Inc.“ geführt wird, erkennt die KI zwei unterschiedliche Entitäten. Wenn Produktinformationen in einem System aktualisiert werden, in anderen jedoch nicht, basieren Entscheidungen auf veralteten Daten. Diese Inkonsistenzen skalieren schnell. Fehler werden verstärkt, Kundenerlebnisse leiden und das Vertrauen in KI-gestützte Ergebnisse sinkt.
Definition: Single Source of Truth im Content-Management
Was ist eine „Single Source of Truth“ (SSOT)?
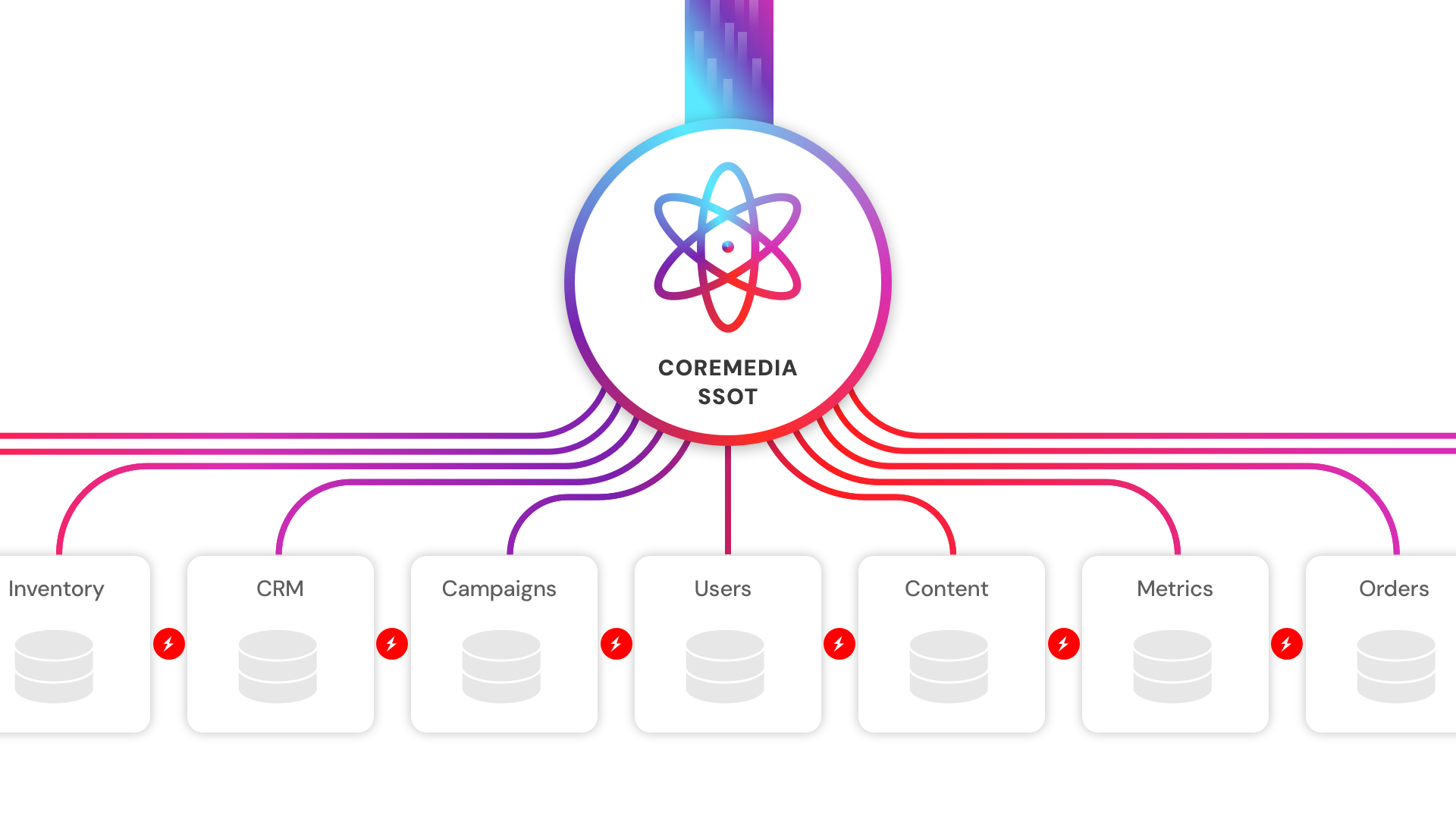
Eine Single Source of Truth ist ein zentraler Referenzpunkt für alle Daten und Inhalte innerhalb einer Organisation. Ein einziges System of Record, auf das alle anderen Tools, Teams und Prozesse zugreifen. Im Content-Management bedeutet das: Sämtliche kundenrelevanten Inhalte, von Webseiten über App-Benachrichtigungen bis hin zu digitalen In-Store-Displays, stammen aus einer zentralen Plattform und werden dort gesteuert.
Entscheidend ist dabei nicht nur, wo Daten gespeichert sind, sondern was passiert, wenn sie sich ändern. In einem SSOT-Modell werden Änderungen einmal vorgenommen und anschließend konsistent über alle Kanäle und Systeme hinweg ausgespielt. Es gibt keine Versionsabweichungen, keine parallele Pflege und keine manuelle Abstimmung.
Für KI ist das der Unterschied zwischen verlässlichen, strukturierten und kontrollierten Daten und einem widersprüchlichen Datenmix.
SSOT-Architektur vs. traditionelle Datenarchitektur
Traditionelle Datenarchitektur wächst meist historisch: ein Data-Warehouse hier, ein separates Content-System dort, dazu punktuelle Integrationen, die bei Bedarf ergänzt werden. Das Ergebnis ist ein System, dessen Datenqualität davon abhängt, wie aktuell die letzte Synchronisation war – was in der Praxis selten ausreichend ist.
Die SSOT-Architektur kehrt dieses Prinzip um. Statt das Data-Warehouse als Endpunkt zu betrachten, wird die Single Source of Truth zur zentralen Quelle. Inhalte und Daten werden an der Quelle verwaltet, konsistent strukturiert und in einer Form bereitgestellt, die downstream Systeme – einschließlich KI – direkt nutzen können. Das Informationssystem wird damit nicht mehr zum passiven Archiv, sondern zu einem aktiven, steuerbaren Business-Asset.

Wie eine Single Source of Truth Enterprise-KI ermöglicht
KI mit präzisen und verlässlichen Daten versorgen
KI ist nur so gut wie die Daten, mit denen sie trainiert wird, und die Informationen, auf die sie im Live-Betrieb zugreift. Präzise Daten im Input sind kein Nice-to-have, sondern die Grundvoraussetzung für Ergebnisse, auf deren Basis Geschäftsentscheidungen getroffen werden können. Wenn Content- und Kundendaten aus einer gesteuerten Single Source of Truth stammen, erhält die KI eine konsistente und verlässliche Datenbasis. Strukturierte, versionierte und governance-geprüfte Daten führen zu Ergebnissen, denen Redakteurinnen und Redakteure, Analystinnen und Analysten sowie Führungskräfte tatsächlich vertrauen können.
Datengetriebene Entscheidungen ermöglichen
Viele Organisationen beschreiben sich selbst als datengetrieben. In der Realität trifft das nur auf wenige zu. Die Lücke entsteht meist dort, wo Daten nicht sauber, nicht zugänglich oder nicht ausreichend vertrauenswürdig sind, um kritische Entscheidungen ohne vorherige manuelle Prüfung zu treffen.
Eine Single Source of Truth verändert diese Logik grundlegend. Wenn Business-User wissen, dass die Daten hinter einem Report oder einer KI-Empfehlung aus einer zentralen, gesteuerten Plattform stammen, können sie darauf vertrauen und entsprechend handeln. Datengetriebene Entscheidungen setzen voraus, dass die zugrunde liegenden Daten tatsächlich zuverlässig sind.
Datenkonsistenz im großen Maßstab sicherstellen
Datenkonsistenz ist einfach, wenn nur ein Team, ein System und ein Kanal existieren. In Unternehmen wird sie jedoch zur größten Herausforderung, sobald Märkte, Business-Units und digitale Touchpoints hinzukommen.
Die Single Source of Truth löst dieses Problem durch ihr Design. Anstatt darauf zu hoffen, dass mehrere Systeme synchron bleiben, stellt das SSOT-Modell sicher, dass alle nachgelagerten Systeme – von Personalisierungs-Engines über KI-Empfehlungssysteme bis hin zu regionalen Content-Teams – auf dieselbe, zentral gesteuerte Produktionsdatenbasis zugreifen.
Datenqualität verschlechtert sich damit nicht mit wachsender Komplexität, sondern skaliert mit dem Unternehmen mit.
Zentrale Bausteine AI-fähiger Datenverwaltung
Die zentrale Rolle von Data Governance
Data Governance beschreibt die Regeln, Rollen und Prozesse, die festlegen, wie Daten innerhalb einer Organisation erstellt, gepflegt und genutzt werden. Ohne diese Governance ist eine Single Source of Truth lediglich ein zentraler Schwachpunkt, also ein konsolidiertes System ohne klare Kontrolle darüber, was hineingelangt oder wer Änderungen vornehmen darf.
Eine wirksame Data Governance umfasst Zugriffskontrollen, Datenqualitätsstandards und Compliance-Anforderungen. In regulierten Branchen wie Finanzdienstleistungen, öffentlichem Sektor oder Gesundheitswesen ist sie unverzichtbar. Aber auch außerhalb streng regulierter Umfelder gilt: Data Governance entscheidet darüber, ob Business-Daten für KI vertrauenswürdig sind oder ob sie zu Fehlentscheidungen führen.
Datenmanagement ohne Governance ist Infrastruktur ohne Richtlinien. Erst das Zusammenspiel beider Elemente ermöglicht skalierbare Enterprise-KI.
Daten über Business-Units hinweg vereinheitlichen
Eine der strukturellen Herausforderungen großer Organisationen besteht darin, dass einzelne Abteilungen eigene Tools, Prozesse und teilweise identische Datenkopien entwickeln. Diese Daten übergreifend zu vereinheitlichen und zu integrieren ist weniger ein technisches als ein organisatorisches Problem.
Die technische Ebene bleibt dennoch entscheidend: Integrationen müssen stabil sein, Plattformen müssen unterschiedliche Content-Typen und Datenquellen unterstützen, und Zugriffe müssen sauber gesteuert werden. Der eigentliche Kern liegt jedoch in der Abstimmung darüber, was die Single Source of Truth umfasst, wer welche Content-Typen verantwortet und wie Workflows gestaltet werden, wenn dieselben Daten von mehreren Teams genutzt werden. Wenn diese Fragen sauber gelöst sind, kann ein und dieselbe Datenbasis Marketing, Produkt, IT und KI gleichzeitig bedienen, ohne Duplikate oder Konflikte zu erzeugen.
Die Lücke zwischen Data-Team und Business-Usern schließen
Ein Data-Team, das präzise und gut gesteuerte Daten bereitstellt, schafft nur dann echten Mehrwert, wenn Business-User darauf basierend handeln können. In vielen Organisationen bricht genau diese Übersetzungsebene jedoch weg.
Der Data Analyst veröffentlicht einen Report, doch das Marketing-Team vertraut ihm nicht, weil die Herkunft der Daten nicht nachvollziehbar ist. Analytics-Tools liefern Erkenntnisse, die ungenutzt bleiben, weil den Nutzerinnen und Nutzern der Kontext fehlt, um sie richtig einzuordnen.
Eine Single Source of Truth reduziert diese Reibung deutlich. Wenn Business-User wissen, dass Inhalte und Daten in ihren Tools aus derselben gesteuerten Quelle stammen wie die Inputs der KI, verkleinert sich die Lücke. Ergebnisse werden nachvollziehbar, Attribution wird transparent, und die Arbeit des Data-Teams führt direkt zu Entscheidungen statt in ungenutzten Dashboards zu enden.
Der Vorteil von CoreMedia: Ein sicherer, konformer Datencontainer
Vom CMS zum strategischen Asset
Die meisten Organisationen betrachten ihr CMS als reines Publishing-Tool. Die CoreMedia Experience Platform ist anders positioniert: als strategisches Asset, das als kontrollierte Grundlage für Content, Kundendaten und Experience-Delivery dient – innerhalb einer einzigen composable Architektur.
Das bedeutet: strukturierte Content-Modelle, klare Ownership-Workflows, Enterprise-Grade-Zugriffskontrollen und die Flexibilität, Inhalte kanalübergreifend ohne Duplikation auszuspielen. Wenn KI-Systeme Kundeninformationen oder Produktinhalte benötigen, greifen sie auf eine einzige, gesteuerte Quelle zu, statt Ergebnisse aus mehreren Systemen zusammenzusetzen.
Gleichzeitig bleibt das System skalierbar für neue Anforderungen wie zusätzliche Märkte, neue Kanäle oder neue KI-Use-Cases, ohne dass die Basis neu aufgebaut werden muss.
Eine vollständige Sicht auf Kundendaten
Personalisierung ohne vollständige Sicht auf Kundendaten ist im großen Maßstab reine Schätzung. Wenn Kundendaten über CRM, Analytics-Plattform und ein Legacy-CMS fragmentiert sind, hat keines dieser Systeme das vollständige Bild – und auch die KI nicht.
- Die integrierte Customer-Data-Platform (CDP) von CoreMedia löst dieses Problem an der Quelle. Sie konsolidiert Kundendaten aus allen Touchpoints in einheitliche Profile, vollständig auf First-Party-Daten basierend – ein wichtiger Faktor, da sich Third-Party-Cookie-Beschränkungen in vielen Märkten weiter verschärfen. Das Ergebnis ist eine umfassende Sicht auf jede Kundin und jeden Kunden, die direkt in die Experience-Delivery einfließt, ohne dass ein separater CDP-Anbieter oder eine manuelle Daten-Integrationsschicht erforderlich ist.
- Eine Single Source of Truth liefert nur dann Mehrwert, wenn die darin enthaltenen Daten unmittelbar handlungsfähig sind. Die Real-Time-Personalization-Engine von CoreMedia ist direkt in dieselbe Plattform integriert, die auch den Content verwaltet. Es gibt keine Verzögerung zwischen einem Kundensignal und der darauf reagierenden Experience. Zielgruppen-Segmente aktualisieren sich dynamisch, Content-Varianten werden auf Basis von Live-Verhaltensdaten ausgespielt, und A/B-Testing läuft inline, ohne Datenexport in ein externes Tool. Das ist der Unterschied zwischen Echtzeit-Personalisierung und Batch-Personalisierung: Daten und Auslieferungsmechanismus teilen sich dieselbe kontrollierte Grundlage, sodass die Reaktion im Moment der Intention erfolgt – nicht erst am nächsten Morgen.
- CoreMedia KIO ist der nativ in die CoreMedia Experience Platform eingebettete AI-Copilot. Im Gegensatz zu generischen KI-Tools, die isoliert arbeiten, hat CoreMedia KIO direkten Zugriff auf Kundendaten, Echtzeit-Performance-Metriken und Brand-Guidelines – alles aus derselben kontrollierten Quelle. Er generiert Inhalte, liefert Verhaltens-Insights und unterstützt Contact-Center-Agents, jedoch erfordert jede erzeugte Empfehlung eine redaktionelle Freigabe vor der Umsetzung. Die menschliche Kontrolle bleibt in jedem Schritt erhalten. Die Ergebnisse sind dadurch durchgehend zuverlässig, da sie auf den tatsächlichen Unternehmensdaten basieren und nicht auf losgelösten Modell-Interpretationen. Das ist der praktische Unterschied zwischen KI, die unterstützt, und KI, die fehlleitet.
Case Study: Wie die Nederlandse Spoorwegen (NS) eine zukunftssichere Content-Architektur aufgebaut haben
Überwindung von Content-Silos für bessere Prozesse
Die Nederlandse Spoorwegen (NS) sind der wichtigste Personenbahn-Betreiber in den Niederlanden und transportieren über eine Million Reisende pro Werktag über ein Netzwerk, das Website, Mobile-App und digitale Touchpoints in Bahnhöfen umfasst.
Hinter dieser Skalierung stand jedoch eine fragmentierte IT-Landschaft. Mehrere Content-Management-Systeme wurden von unterschiedlichen Abteilungen genutzt. Inhalte wurden dupliziert, inkonsistent gepflegt und über Kanäle hinweg nur mit erheblichem Aufwand aktualisiert.
Wenn dieselbe Information auf Website, App und Bahnhof-Displays erscheinen sollte, war manuelle Arbeit in mehreren Systemen erforderlich. Genau diese Art von menschlichem Aufwand skaliert schlecht, erhöht die Fehleranfälligkeit und verschlechtert die Datenqualität, auf die KI später angewiesen ist.
Mit mehr als 1.500 digitalen Fachkräften in verschiedenen operativen Clustern war der Koordinationsaufwand erheblich, und das Risiko inkonsistenter Fahrgastinformationen durch isolierte Datenbestände permanent vorhanden.
Eine Grundlage für Insights und zukünftige KI-Anwendungen
NS arbeitete gemeinsam mit IBM iX und CoreMedia daran, eine einheitliche, headless Content-Plattform aufzubauen, die als Single Source of Truth für alle fahrgastbezogenen Inhalte dient.
Ziel war eine Architektur, die sowohl Echtzeit-Datenbereitstellung als auch zukünftige KI-Fähigkeit ermöglicht.
CoreMedia ist heute mit einem Static-Site-Generator verbunden, der HTML-Seiten vorab generiert, um eine schnelle Auslieferung und konsistente Performance sicherzustellen. Alle Kommunikationskanäle sind über eine Integrationsschicht vereinheitlicht, während Inhalte und Assets zentral aus einer Quelle verwaltet werden.
Das Ergebnis ist eine modulare, skalierbare Omnichannel-Content-Infrastruktur, die menschliche Fehler reduziert, Echtzeit-Updates unterstützt und die gesteuerte Datenbasis bereitstellt, die zukünftige KI- und Insight-Use-Cases benötigen werden.
Schritte zur Implementierung einer AI-fähigen CMS-Infrastruktur
Bestehende Content-Bestände auditieren
Bevor eine Single Source of Truth aufgebaut werden kann, muss klar sein, wo sich die Business-Inhalte tatsächlich befinden. Dafür werden alle Datenbestände systematisch über verschiedene Systeme und Quellen hinweg erfasst – welcher Content existiert, wo er entsteht, wer die Verantwortung trägt und wie er aktuell synchronisiert wird oder eben nicht. Dieses Audit ist selten glamourös, aber es ist der einzige Weg, den tatsächlichen Umfang der Fragmentierung zu verstehen. Die meisten Organisationen entdecken dabei mehr Content-Quellen als erwartet.
Datenzugriff und Sicherheit etablieren
Sobald der Ist-Zustand klar ist, folgt die Gestaltung der Governance-Schicht für das neue System. Dazu gehören Zugriffsrechte – also wer welche Content-Typen lesen, erstellen oder bearbeiten darf – sowie Freigabe-Workflows, die Qualität vor der Veröffentlichung sicherstellen.
Die Migration in ein zentrales System erfordert außerdem klare Entscheidungen darüber, welche Daten übernommen werden und welche abgeschafft werden. Nicht jeder Datenbestand ist migrationswürdig. Ein neues System, das die Inkonsistenzen des alten Systems übernimmt, löst das Problem nicht, sondern zentralisiert es lediglich. Zugriffskontrollen, Ownership-Strukturen und redaktionelle Workflows müssen daher vor Beginn der Migration definiert werden, nicht erst danach.
Fazit: Die KI-Zukunft aktiv absichern
Die nächsten Schritte
Die Organisationen, die 2026 messbare KI-Returns erzielen, haben eine gemeinsame Eigenschaft: Sie betrachten ihre Dateninfrastruktur als strategische Voraussetzung und nicht als nachgelagerte Aufgabe. Sie investieren früh in Data Governance, in die Vereinheitlichung von Daten über Systeme hinweg und in den Aufbau einer Single Source of Truth, bevor sie KI skalieren.
Die technische Infrastruktur für KI ist heute für jedes Unternehmen verfügbar. Der entscheidende Unterschied liegt in der Governance-Infrastruktur – also in einer kontrollierten, konsistenten und verlässlichen Datenbasis. Genau diese trennt die wenigen Organisationen, die nachweisbaren KI-Mehrwert generieren, von der Mehrheit, die nicht über Proof-of-Concepts hinauskommt.
Wenn KI-Initiativen ins Stocken geraten, liegt die Ursache selten im Modell. Sie liegt fast immer in der Grundlage.
Eine Demo zeigt, wie die CoreMedia Experience Platform als Single Source of Truth für eine Enterprise-KI-Strategie eingesetzt werden kann.



